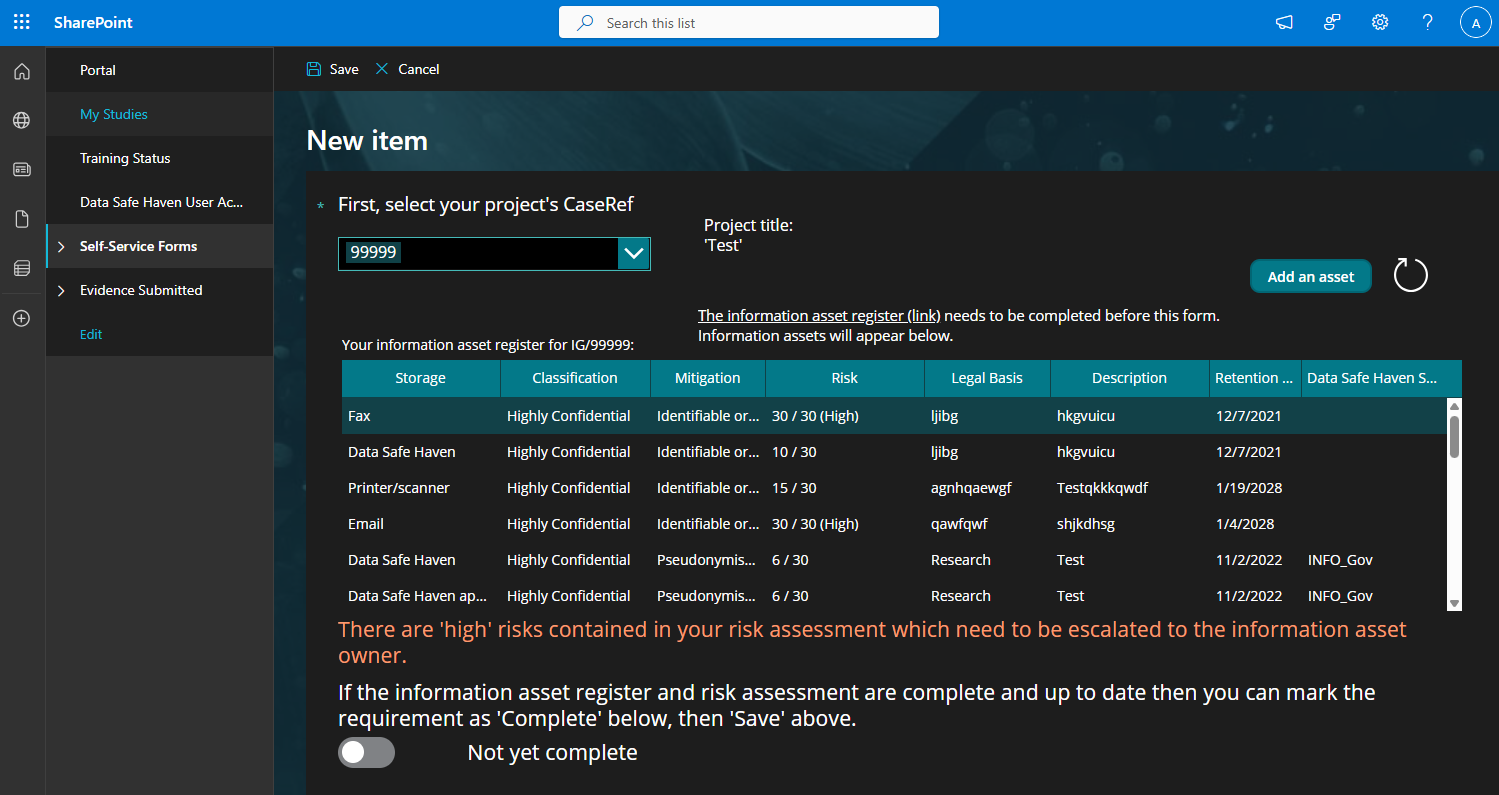
IG Migration
ISD Architecture
2026-02-14
What?


- Front end + Data store for the Information Governance Assurance function
- Running for >10 years
- Source of truth of unique identifiers, approval status, privileged roles for all registered research involving sensitive data at UCL
- Stored in SharePoint lists
- Workflows built with Power Automate
Why migrate?
Data availability and user experience had become very poor






Why migrate?
- SharePoint also generally fragile, and in this case:
- No relational data across SharePoint lists
- No validation or uniqueness enforced
- Little automation so many tasks manual repetitive
- Original site creators no longer at UCL
- New home for the data and front end
- ARC Services Portal
- Postgres DB with extensible APIs on top
![]()
Researchers and Studies
Researchers have Agreements and Training Status
Studies have Owners, Assets and Contracts

UI looks like this…
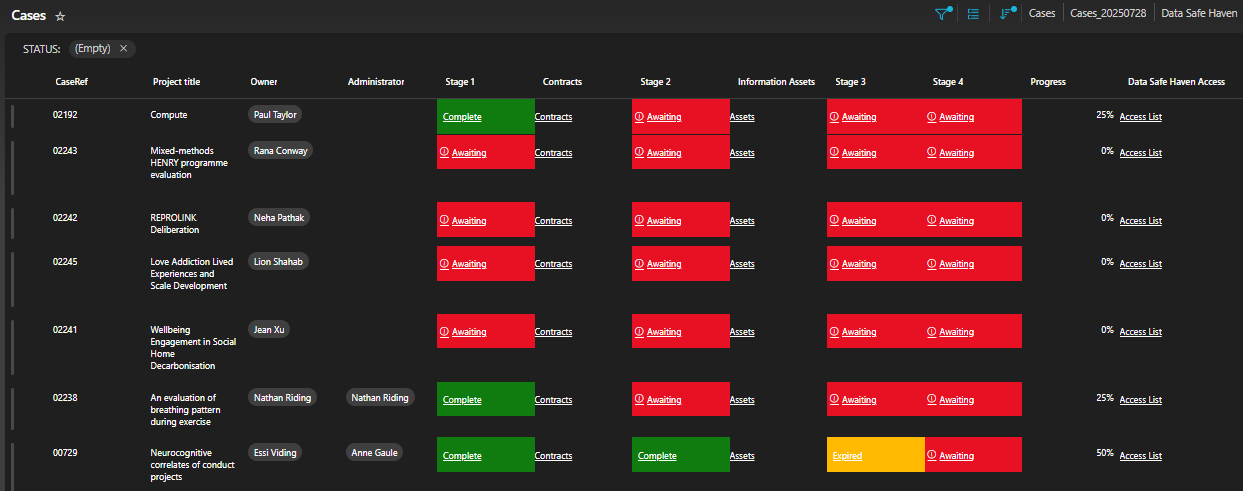
and this…
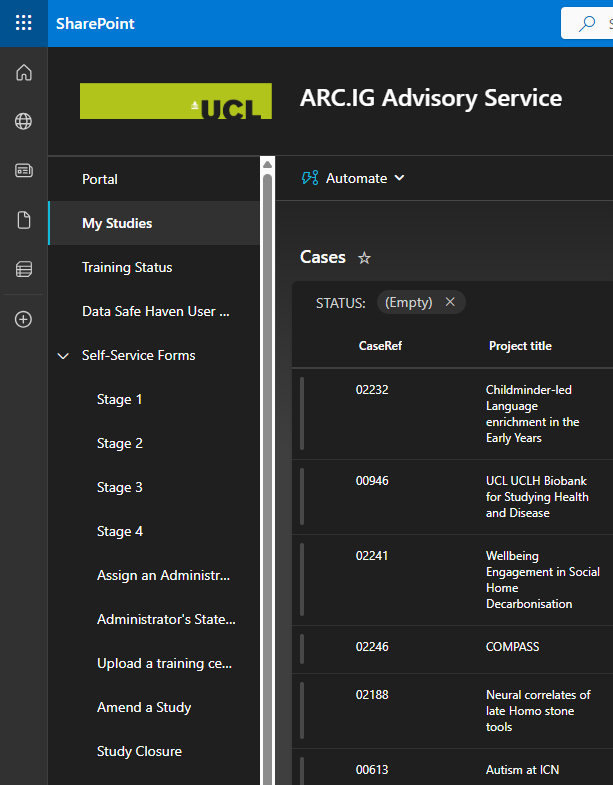
and… this…